Microsoft SQL Server Database Design Principles – (Part 2)
Author: Basit A. Farooq
Relationships
Relationships identify associations between data stored in different tables. Entities relate to other entities in a variety of ways. Table relationships come in several forms:
· One-to-one relationship
· One-to-many relationship
· Many-to-many relationship
One-to-one relationship
A one-to-one relationship represents a relation between entities in which one occurrence of data is related to one and only one occurrence of data in related entity. For example, every employee should have payroll record, but only one payroll record.

One-to-many relationship
The one-to-many relationship seems to be the most common relationship that exists in relational databases. In one-to-many relationship, each occurrence of data in one entity is related to zero or more occurrences of data in a second entity. For example, each department in a Department table can have one or more employees in the Employee table.
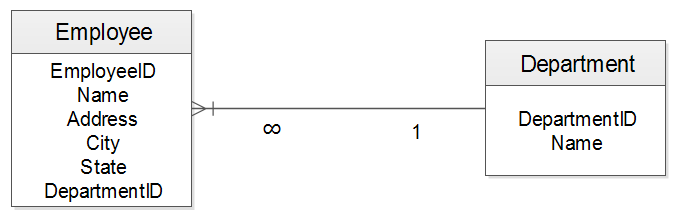
Many-to-many relationship
In a many-to-many relationship, each occurrence of data in one entity is related to zero or more occurrence of data in the second entity and, at the same time, each occurrence of second entity is related to zero or more occurrences of data in the first entity. For example, one instructor teaches many classes and one class are taught by many instructors.

The many-to-many relationship often causes problems in practical examples of normalized databases, and therefore, it is common to simply break many-to-many relationships in a series of one-to-many relationship.
Data Integrity
Data integrity assures accurate data in the database. Within the scope of the database, you enforce data integrity with database objects, such as constraints. Constraints ensure that data within the database is reliable and adhere to business rules. Data integrity falls into the following categories:
· Domain integrity
· Entity integrity
· Referential integrity
· User-defined integrity
Domain integrity
Domain integrity ensures that the values of the specified columns are legal, which means that the value meets a specified format and value criteria. For example, to specify the domain integrity for the attribute of the credit card, you can specify that a column of the credit card must have atleast 16 characters input, and the input value should be an integer value.
You can enforce domain integrity by restricting the type (through data types), the format (through CHECK constraints and rules), or the range of possible values (through FOREIGN KEY constraints, CHECK constraints, DEFAULT definitions, definitions NOT NULL and rules).
Entity integrity
Entity integrity ensures that every row in the table is uniquely identified by requiring a unique value in one or more key columns of the table. For example, if you have a table that contains customer information, identify each customer as unique.
You enforce entity integrity through indexes, UNIQUE KEY constraints, PRIMARY KEY constraints, or IDENTITY properties.
Referential integrity
Referential integrity ensures that data is consistent between related tables. For example, in a Sales database, you might have one table (Orders) tracking general information about orders and another table (OrderDetails) tracking detailed information about individual order. You would create a relationship between these two tables, relating each order to obtain specific information about order. When you add a new record to the OrderDetails table, the SQL Server database engine verifies that it relates to an existing order record in Orders table, checking for a valid cross-reference between these two tables. If an order needs to be removed from the Orders table, all references to the order must first be deleted in OrderDetails, the child table.
You enforce referential integrity through PRIMARY KEY constraints and FOREIGN KEY constraints.
User-defined integrity
User-defined integrity (also called policy integrity) is a process of ensuring that the values stored in the database remain consistent with established business policies. You maintain user-defined integrity through business rules.
You enforce user-integrity through stored procedures and triggers.
Primary key
A primary key is the combination of one or more column values in a table that ensures that each row of the table is unique. Primary key is usually used to join tables. SQL Server does not require you to define a primary key when you create a table, but usually you want to define a primary key for each table to force each row to be uniquely identifiable. Only one primary key is allowed per table, and the values in in a primary key columns must be unique at all times, so they cannot include NULL or duplicate values. Examples of appropriate primary key values include: national insurance number, driver’s license number, user-allocated ID or code, etc.
Unique key
A unique key is the combination of one or more columns that uniquely identifies each table row. Unique keys are different from the primary key because you can define multiple unique constraints for a table. Moreover, the columns used to define a unique constraint can contain NULL values. Examples of appropriate unique key values include: supplier name, department name, email, etc.
Foreign key
A foreign key consists of one or more column values from a table that refer to a unique key or primary key in another table. Foreign keys are defined in child tables. When a table has a foreign key, SQL Server ensures that parent table record is created before the child record. Conversely, a SQL Server also ensures that the child record is deleted before the parent table record. For example, OrderDetails in Sales database is linked to the Orders table.
Data normalization basics
Normalization is the process of reducing or completely eliminating the occurrence of redundant data in the database. Normalization refers to the process of designing the relational database tables from the entity-relationship (ER) model. Normalization is a part of the logical design process and is a requirement for online transaction processing (OLTP) databases. Normalization is important because it eliminates (or reduce as much as possible) the redundant data. During the normalization process, you usually split large tables with many columns into one or more smaller tables with the smaller number of columns. The main advantage of normalization is to promote data consistency between tables and data accuracy by reducing the redundant information that is stored. In essence, the data only needs to be changed in one place if an occurrence of the data is stored only once.
The disadvantage of normalization is that it produces many tables with a relatively small number of columns. These columns have then to be joined together in order to retrieve the data. Normalization could affect the performance of database drastically. In fact, the more the database is normalized, the more performance will suffer.
The normal forms
Traditional definitions of normalization refers to the process of modifying the database tables to adhere to the accepted normal forms. The normal form are the rules of normalization. A normal form is a way of measuring levels, or depth, to which a database is normalized. There are five different normal forms; however, most database solutions are implemented with third normal form (3NF). Both forth (4NF) and fifth (5NF) normal forms are rarely used, and hence, not discussed in this chapter. Each normal form builds from previous. For example, 2NF cannot begin before the 1NF is completed.
“A detailed discussion of all normalization forms is outside the scope of this article series. For help with this, refer to Wikipedia article: http://en.wikipedia.org/wiki/Database_normalization”
First normal form (1NF)
In first normal form (1NF), you divide the base data into logical units called entities or tables. When you design each entity or table, you assign the primary key to it, which uniquely identifies each record inside table. You create a separate table for each set of related attributes. There can be only one value for each attribute or column heading. The 1NF eliminates repeating groups by putting each in a separate table and connecting them with a one-to-many relationship.
Second normal form (2NF)
The objective of the second normal form (2NF) is to avoid duplication of data between tables. In 2NF, you take the data that is partly dependent on the primary key and enter it into another table. The entity is in 2NF when it meets all the requirements of 1NF and has no composite primary key. In 2NF, you cannot subdivide the primary key in separate logical entities. You also eliminate functional dependencies on partial keys by putting those fields in a separate table from those that are dependent on the whole key.
Third normal form (3NF)
The third normal form (3NF) objective is to remove the data in a table that is not dependant on the primary key. In 3NF, no non-key column can depend on another non-key column, so that all data apply specifically to the table entity. The entity is in 3NF when it meets all the requirements of 1NF and 2NF, and there no transitive functional dependency.
Denormalization
Denormalization is the reverse of normalization process in which you combine smaller tables that contain related attribute. The applications such as online analytical processing (OLAP) applications are good candidates for denormalized data. This is because all the necessary data in one place, and SQL Server does not require combining data when queried.